You might be hearing about "vector databases" more often lately, and there's a good reason why. This emerging concept is gaining traction within the developer community for its potential to revolutionize data management.
The spotlight on vector databases has intensified as developers recognise their ability to supercharge the performance of Large Language Models (LLMs) through techniques such as Retrieval Augmented Generation (RAG). These databases offer a novel approach to handling complex data structures, opening up new possibilities for applications ranging from natural language processing to recommendation systems.
In this short overview, we'll discuss the core principles of vector databases, covering their basic concepts and operational dynamics such as vector embeddings, vector search, and the use of distance metrics for effective data retrieval. We will also touch on their practical uses and the range of tools available for leveraging vector databases.
First, let’s begin by setting the stage.
In their most basic level, vectors are essentially arrays. While mathematical vectors are about direction and magnitude in physical spaces, vectors in a vector database are about representing data, especially complex data like images, text, and audio, in a form that can be efficiently searched and analyzed.
In other words, think of vectors as a list of numbers, each lined up in a row or a column, with each number in this array having a purpose and a place.
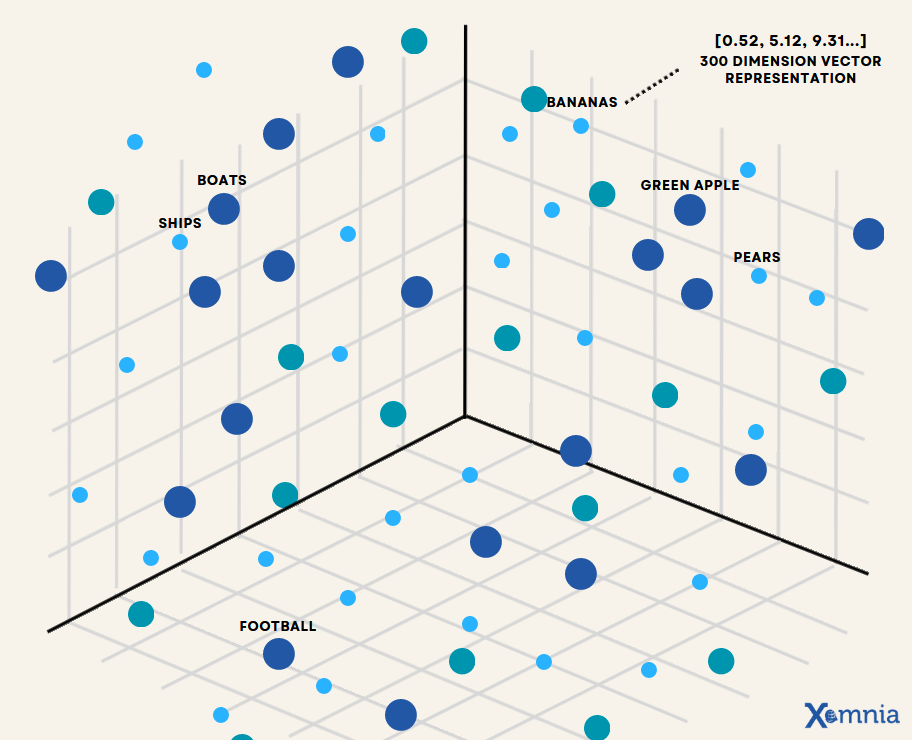
Vector embeddings are numerical interpretations that retain the contextual significance of data (see Figure 1), facilitating the alignment of similar entities within a vector space for similarity searches. Vector embeddings numerically capture the semantic meaning of the objects in relation to other objects. Thus, similar objects are grouped together in the vector space, which means the closer two objects are, the more similar they are.
For example, closely related concepts like "Boats" and "Ferries" may be positioned near each other due to their contextual links.
However, representing complex data, such as words, sentences, or longer text segments as meaningful numerical arrays is not easy. This is where machine learning models come in: They enable us to represent the contextual meaning of, e.g., a word as a vector, because they have learned to represent the relationship between different words in a vector space. These types of machine learning models that can generate embeddings from unstructured data are also called embedding models or vectorizers.
It's worth noting that every embedding model typically employs a distinct mechanism for generating word embeddings or vectors. For instance, OpenAI's text-embedding-ada-002 model is specifically crafted to produce word embeddings utilised by variations like text-davinci-003 and gpt-turbo-35. Similarly, Google's PaLM 2 leverages the embedding-gecko-001 model to generate embedding vectors, each tailored to suit the specific requirements and objectives.
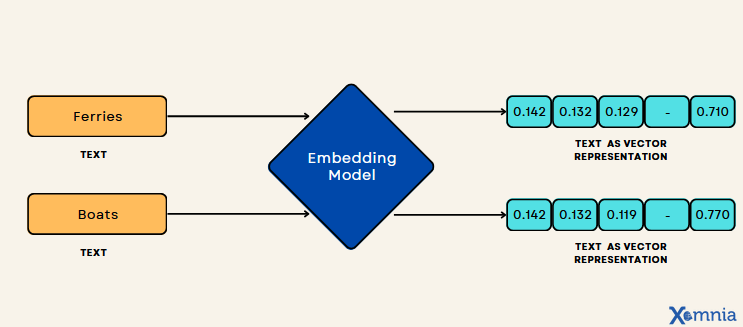
Figure 1. Text-to-Vector Transformation Using an Embedding Model
Vectors serve as a bridge for machines to make sense of the world. Here's why we use them:
Vectors capture not just raw data, but also its context and semantics. This means that similar concepts are represented by vectors that are close to each other in the vector space, enabling machines to grasp semantic similarities.
Vectors transform complex, unstructured data into a simple, uniform format—an array of numbers. This transformation allows machines to process and analyse data efficiently.
A vector database specializes in storing, indexing, and retrieving data represented as vectors or vector embeddings. These databases are designed to manage large volumes of unstructured and semi-structured data, offering features like metadata storage, filtering, scalability, dynamic updates, and security. The use of embedding models allows vector databases to measure and understand the similarity between data objects, facilitating advanced search capabilities across high-dimensional vector spaces. A representation of how vector embeddings might be distributed in such a space is illustrated in Figure 2.
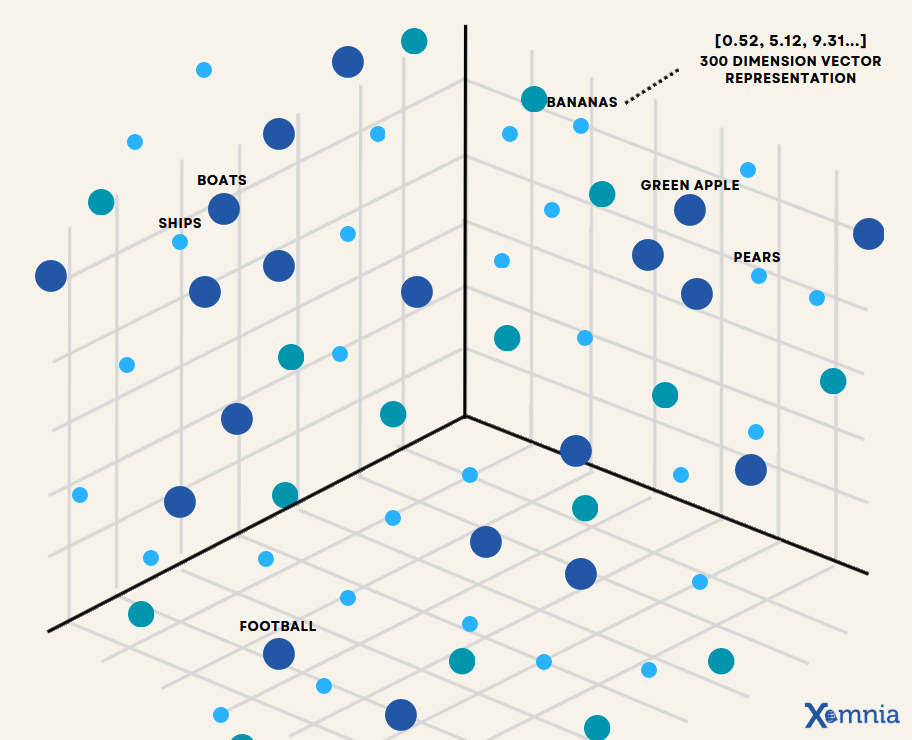
Figure 2. Space Representation of Vector Database
Vector databases function through a combination of vector search, distance metrics, and vector indexing. These components work together to enable efficient retrieval of relevant data by comparing similarities between vectors, quantifying these similarities using distance metrics, and organising vector embeddings for streamlined retrieval operations. Let's explore each of these components to understand how vector databases function.
At the core of vector databases is the concept of vector search. This process involves comparing the similarity between vectors, where each vector represents an object or data point. By analyzing the semantic meaning encoded within these vectors, the database can efficiently retrieve objects that are similar to a given query vector.
To quantify the similarity between vectors, distance metrics are used. Common distance metrics include Euclidean distance, Manhattan distance, and cosine similarity. These metrics calculate the "distance" between vectors in multi-dimensional space, helping to identify the most relevant search results based on their proximity to the query vector. For an in-depth understanding of distance metrics in vector search, explore this Weaviate article.
Efficient data retrieval is crucial for the performance of vector databases, especially when dealing with large-scale datasets. Vector indexing is the process of organizing vector embeddings in a structured manner to expedite retrieval operations. Techniques such as clustering and indexing algorithms like Hierarchical Navigable Small World (HNSW) are commonly employed for this purpose.
To see an overview of these concepts in action, Figure 3 illustrates a content-based retrieval workflow using vector space embeddings, demonstrating how documents, images, and audio can be transformed into vector representations and retrieved through an Approximate Nearest Neighbour (ANN) search.
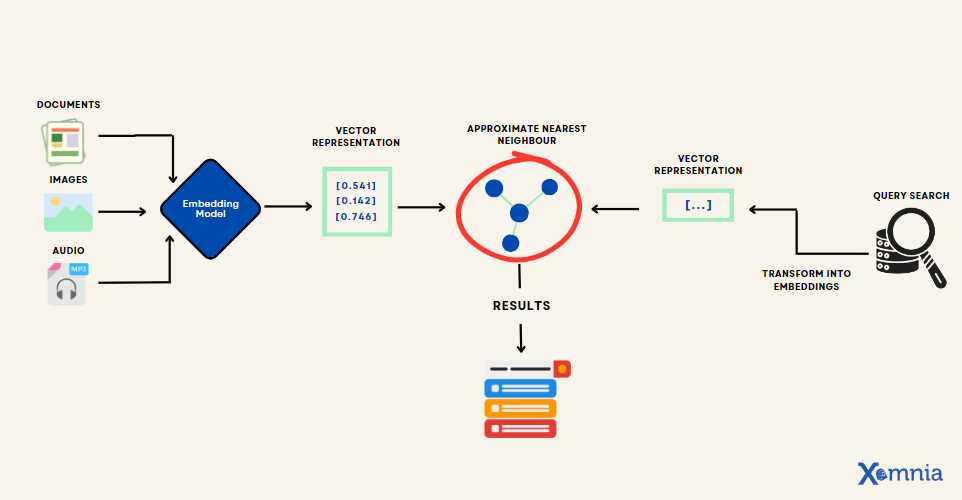
Figure 3. Content-Based Retrieval Workflow Using Vector Space Embeddings
Continuing from our exploration of the foundational components—we now delve into the critical roles of metadata filtering and namespaces in refining query searches within these databases. These additional features significantly enhance the functionality and user experience of vector databases by providing more targeted and relevant search results.
Metadata filtering is a technique that allows users to refine their search or query results beyond just vector similarities. This involves using additional information (metadata) associated with the vectors for filtering results according to specific criteria. This metadata can include various attributes like categories, tags, or any other descriptive information related to the vector data (as shown in Figure 4). By leveraging metadata filtering, our searches can consider specific characteristics or classifications that align with the query's intent beyond vector similarity.
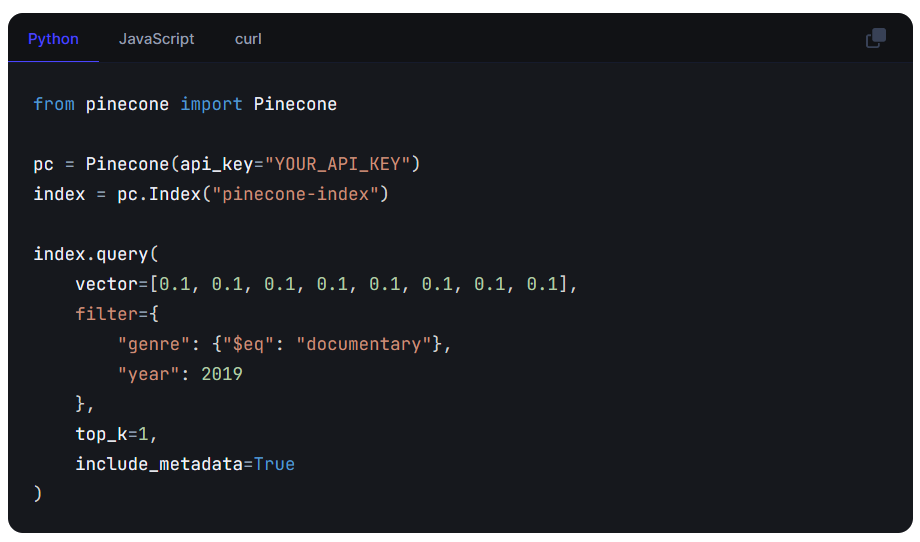
Figure 4. Filtered Query for 2019 Documentaries (Courtesy of Pinecone)
Namespaces bring an organized approach to managing data within vector databases, similar to how libraries segment books into various sections like fiction, non-fiction, science, or history, making it easier to locate specific types of books. In vector databases, namespaces fulfil a similar purpose by categorizing and separating vector data into distinct groups or domains and directing users to the information they seek more efficiently. This organization not only accelerates the search process but also increases the chances of finding the desired data quickly. It's like going directly to the history section when researching a history topic, without the need to search through the entire library.
Check out Pinecone’s documentation for a detailed guide on leveraging namespaces and metadata filtering.
When considering how to optimize your database architecture for speed and efficiency, understanding the implications of choosing between namespaces and metadata filtering becomes essential. One crucial guideline to remember is that searches are limited to one namespace at a time; this means that you cannot span your query across multiple namespaces simultaneously.
This limitation means you should carefully consider your use-case and application when deciding how to structure your data, keeping in mind the impact on search speed and operational efficiency. For instance, if your project might require combining insights from both science textbooks and literature novels—like analyzing the frequency of scientific terms in literature—you'd benefit from a setup that leverages metadata to tag and filter your data across these different types. Metadata allows for a more flexible search strategy, enabling you to cross-reference data from various namespaces when needed, albeit with a potential trade-off in search speed due to the broader search scope and the computational overhead of filtering through extensive metadata.
On the other hand, if your searches are more straightforward and confined to specific, well-defined categories—such as looking only within science textbooks for a particular experiment or within literature novels for character analysis—then organizing your data with namespaces is an efficient strategy. This approach not only simplifies your data structure, but can also significantly enhance search speed by limiting the query scope to a specific namespace, reducing the amount of data to sift through and allowing for quicker retrieval times.
The primary application of vector search engines, unsurprisingly, centers around search functionality. Leveraging the power of a vector database to identify similar items makes it exceptionally well-suited for scenarios where users seek akin products, movies, books, songs, and more. This capability also seamlessly extends to recommendation systems, where the goal of finding similar items is reframed as suggesting items based on user preferences or past interactions.
Thus, vector search engines play a pivotal role in enhancing user experiences by precisely matching search queries with relevant results or suggestions. This in turn makes them indispensable in creating dynamic, personalized content recommendations.
Many leading companies leverage vector databases to power innovative features and services, demonstrating their practical value:
Platforms like Spotify and Pinterest utilize vector databases to fine-tune their recommendation algorithms, offering users more personalized content.
Financial institutions employ vector databases for analyzing transaction patterns and identifying fraudulent activities through behavioral similarities.
Google's search engine benefits from vector databases in processing natural language queries, enabling it to deliver more relevant search results.
Essentially, the main difference between a traditional (relational) database and a modern vector database comes from the type of data they were optimized for. While a relational database is designed to store structured data in tabular form, a vector database is also optimized to store unstructured data and their vector embeddings.
Because vector databases and relational databases are optimized for different types of data, they also differ in the way data is stored and retrieved. In a relational database, data is stored in columns and retrieved by keyword or wildcard matches in traditional search. In contrast, vector databases also store the vector embeddings of the original data, which enables efficient semantic search. Because vector search is capable of semantic understanding of your search terms, it doesn't rely on retrieving relevant search results based on exact matches, which makes it robust to typos and synonyms.
Expanding on the discussion above, consider a scenario where you maintain a database of movie quotes and wish to find all quotes related to the theme of love. In a relational database, this would necessitate specifying each variation of the word love in your query (e.g., contains "love", or contains "romance", or contains "affection", etc.). However, with semantic search powered by a vector database, you could simplify this process by searching for the broader concept of "love". This approach, illustrated in Figure 5, not only simplifies the query but also ensures you capture all relevant quotes associated with love, without needing to list every synonym or related term individually.

Figure 5. Traditional vs. Semantic Search: Finding Quotes on Love
Traditional relational databases have been the backbone of data storage and management for decades, and in the evolving landscape of data management, the question often arises: Why not simply store vector data in traditional relational databases?
Well, while it's technically feasible, several critical limitations quickly become apparent to storing vector data in traditional relational databases, highlighting why vector databases are not just an innovation, but a necessity for modern data needs.
Here are a few reasons why vectors and relational databases don't mesh well:
Storing high-dimensional vectors as blobs or in tabular forms leads to performance bottlenecks. The computational cost of similarity calculations in relational models is prohibitively high.
Relational databases are optimized for exact matches and range queries. However, they struggle with similarity searches in high-dimensional vector spaces, which are essential for many modern applications.
As the volume of vector data grows, traditional databases have difficulty scaling efficiently due to their rigid schema requirements and the complexity of managing high-dimensional data.
While vector-capable databases such as SQLite with SpatiaLite and PostgreSQL with PostGIS have indeed embraced vector support, their approach often stops short of indexing the vector embeddings. This omission is not trivial; without proper indexing, vector search operations tend to be sluggish, undermining the performance benefits that vector data promises. Vector databases, on the other hand, prioritise efficient indexing of vector embeddings, enabling faster and more accurate search operations.
The landscape of vector search solutions also includes vector indexing libraries, which share some similarities with vector databases in facilitating fast vector search.
Vector indexing libraries, however, primarily focus on storing vector embeddings in in-memory indexes, leading to two significant limitations:
Data within most vector indexing libraries is immutable. Once indexed, the data cannot be updated in real-time, which poses challenges for dynamic datasets that require frequent updates.
The in-memory storage model of vector libraries limits their scalability, especially in scenarios that involve importing large volumes of data. This limitation becomes increasingly problematic for applications that need to process millions or even billions of objects.
In a nutshell, vector libraries serve as an effective solution for static datasets where real-time updates and scalability are not critical. However, for applications demanding scalable, real-time semantic search capabilities at a production level, the limitations of vector libraries become apparent.
Indexing is a critical component that enhances the performance of vector databases. By organizing data in a way that makes similarity searches more efficient, indexing techniques reduce the time and computational resources required to find relevant results in large datasets.
Some of the innovative indexing methods used in vector databases include:
We won’t go too far into this, but Pinecone presents an excellent article on this topic.
Vector databases have quickly become indispensable in the tech landscape, especially among those working with LLMs. Beyond the obvious efficiency in semantic search, scalability, and dynamic knowledge access, there are underlying reasons that explain the burgeoning popularity of vector databases.
LLMs and transformer models, like GPT-4, are proficient in understanding and generating human-like text via contextualized vector embeddings, enabling responses that are not just relevant but also deeply rooted in the context of the query.
The nature of these vector embeddings requires an efficient storage solution that can handle indexing and querying. One of the most compelling advantages of vector databases lies in their ability to alleviate the computational burden associated with LLMs. By storing vectors in a centralised database, LLMs can bypass the need for recalculating embeddings with each input during inference. This streamlined process not only enhances response times but also significantly reduces computational costs, making LLMs more efficient and scalable.
Read further: How to transform any website into a chatbot using LLMs?
A characteristic of LLMs is their static knowledge base post-training, which remains unchanged unless updated with new data. Vector databases address this limitation head-on, providing a dynamic avenue for LLMs to access and integrate new information. This integration breathes life into LLMs, granting them a semblance of state and adaptability that was previously unattainable.
On that note, LLMs typically encounter issues of factual accuracy when navigating beyond their training confines, often manifesting as "hallucinations" (responses confidently delivered yet factually incorrect). Vector databases present a potent solution through Retrieval-Augmented Generation (RAG), leveraging a vector search engine to source factual knowledge that LLMs can incorporate in real-time. This process significantly bolsters the model's capacity to generate responses that are not only accurate but richly contextual, effectively reducing the incidence of hallucinations.
Vector databases can be quite enticing. With their ability to handle high-dimensional data efficiently, they represent a leap forward in data processing capabilities. However, the decision to implement a vector database is not one-size-fits-all one, and before taking the plunge, it's crucial to consider several key factors that can make or break your implementation.
1. Dynamic Data Requirements: How Often Does Your Data Change?
In the fast-paced world of modern data analytics, the rate of data change can vary significantly depending on the application. For organizations dealing with rapidly evolving datasets or real-time data streams, the ability to update and query data in real-time is paramount. Vector databases, with their focus on performance and efficiency, may not always be the best fit for highly dynamic data environments.
Consider a ride-sharing company operating in a dynamic urban environment. With data constantly changing due to ride requests, driver locations, and traffic conditions, real-time processing is essential for seamless service delivery. Traditional databases may struggle to keep up with the high volume and velocity of data generated by the ride-sharing platform. In contrast, vector databases offer a more efficient solution by representing each driver, passenger, and location as a vector embedding. This enables quick and accurate spatial and similarity queries, facilitating real-time matching of drivers with passengers and route optimization.
2. Complexity of Operations: Do Your Operations Require Specialized Capabilities?
One of the primary strengths of vector databases lies in their ability to perform specialized operations on high-dimensional data efficiently. Tasks such as similarity searches, clustering, and classification, which are commonplace in machine learning and spatial analysis, can be performed with ease using vector databases.
Take, for example, a machine learning model trained to classify images based on their content. The model generates high-dimensional embeddings for each image, which are then stored in a vector database for efficient retrieval and comparison. By leveraging the specialized operations offered by the vector database, such as cosine similarity or Euclidean distance calculation, the model can quickly identify similar images and make accurate predictions.
3. Data Volume and Utilization: Is Your Data Volume Sufficient to Justify a Vector Database?
Perhaps the most critical consideration when evaluating a vector database is the volume and density of your data. While vector databases excel at handling large volumes of high-dimensional data efficiently, they may not be the best fit for organizations with relatively small or sparse datasets.
Consider the case of a startup exploring the use of machine learning for personalized content recommendations. While the potential benefits of a vector database are undeniable, the limited size of their user base and the sparse nature of their data may be overkill and cannot justify the investment in a vector database at this stage. For smaller use cases, storing vectors in-memory might suffice. This approach is simpler and offers rapid access to vector data, but comes with its own set of considerations.
The evolution of vector databases is closely tied to advancements in AI and ML, particularly in the development of more potent embeddings and the creation of hybrid databases that combine the strengths of traditional relational databases with vector databases. This ongoing innovation is expected to further enhance the efficiency, scalability, and versatility of vector databases in managing complex data landscapes.
This beginner's guide to vector databases sheds light on their foundational concepts and the transformative potential they hold for data management and analysis. As technology continues to advance, the role of vector databases in enabling efficient and intelligent data processing is becoming increasingly significant, marking a new era in the exploration of unstructured and semi-structured data.
Xomnia is a leading data and AI firm based in Amsterdam with a team of experts. If you are interested in what we can do for your business, you can contact us here!

We are looking more closely recently at EU cloud providers due to geo-political tensions. See a previous blog for more info. In our research on the capabilities of EU clouds we noticed that the support for so-called analytical databases is mostly la...

A common frustration among expats working at Xomnia is the occasional struggle with the communication style of the Dutch government. When a colleague accidentally missed a deadline on a fine which turned out to be a fine for missing a fine, this “fi...
The AI landscape is evolving at an immense pace, with recent developments signaling a significant shift towards connectedness of LLMs, Agents and third-party applications. Most recently, industry leaders like Anthropic and Google open-sourced their...



