
MLOps is usually a daunting concept, mainly due to the number of principles and technologies it requires, as well as its wide-reaching scope within a team or company.
However, it does not need to be so.
The most crucial considerations to keep in mind when working with MLOps are the needs of your team, users and projects. This is extremely crucial because different teams have different needs. This fact should be the foundation for any team looking to apply MLOps principles on their projects. Consequently, no matter how many tutorials and guides one follows, they will never match the use case(s) in question by 100%.
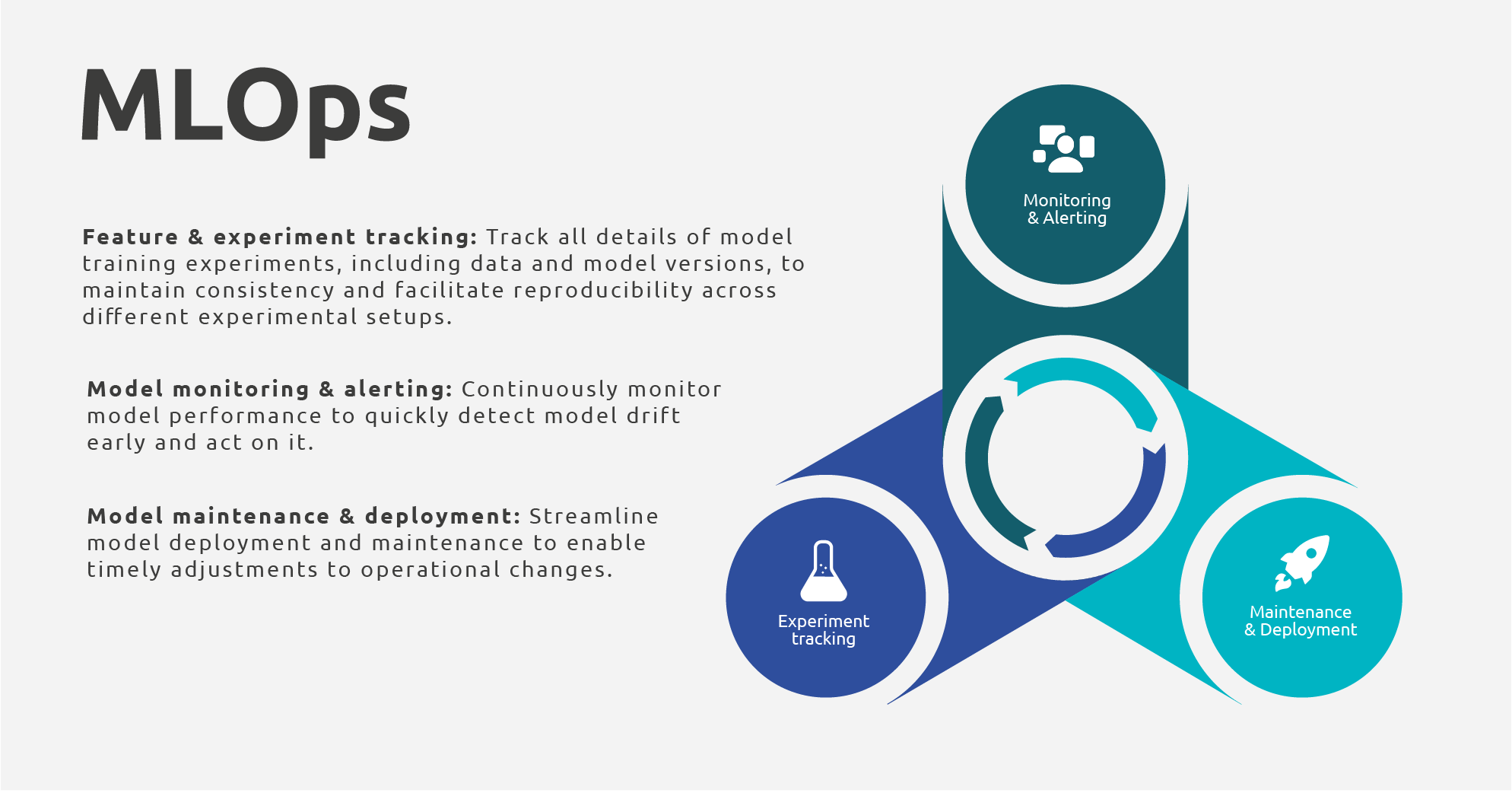
The aim of this blog is to support teams in planning the application of MLOps principles in their projects. This is achieved by looking into the following MLOps best practices from a conceptual point of view, grouped in the following three domains:
- Feature and Experiment Tracking
- Monitoring and Alerting
- Maintenance and Deployment
Since each team has different needs, each of these principles needs to be adopted on the different levels of maturity. For example, in the case of a solution developed for the banking sector, where the prerequisites for data versioning are strict, Feature and Experiment Tracking can be more mature from the early stages of the project. On the other hand, a solution in its early stages usually requires a lower level of maturity for Monitoring and Alerting.
The following sections provide a detailed explanation of each of the three domains. Each one is broken down into the following four stages of maturity to help teams organize their efforts according to their projects’ needs:
- Manual
- Basic
- Automated
- Integrated
As a disclaimer, maturity on MLOps goes hand in hand with data maturity and general technical expertise within the team and the company in general. As team members mature technically and the use cases they tackle mature as products, it becomes more demanding to keep delivering value consistently and reliably. For example, larger teams with process-critical products require more structure than smaller teams developing PoC projects. The nature of your team and company should be the main driver in planning the implementation of MLOps principles in your way of work.
Read further: MLOps Fundamentals: How to get value from your machine learning model?
MLOps maturity levels explained
This section will provide an introductory overview of the concept of "levels of maturity" to facilitate understanding the following sections. The levels of maturity discussed below follow a similar pattern for each domain.
On the first (manual) level maturity, you can expect actions to be manual and ad-hoc and usually any tools used for this purpose are either under-utilized or not fit-for-purpose.
On the second (basic) level of maturity, actions are still mostly manual but processes start to emerge to direct these actions. Basic automation could also be possible, facilitated by dedicated tooling and platforms. During these first two stages of maturity, MLOps domains are mostly isolated from each other and any interaction is achieved through manual effort and manual translation of insights into action.
Moving on to the third level of maturity (automated), processes for different principles are formally defined within the team and are fit-for-purpose tools, which facilitate best practices and are part of the team’s formal way of work. The combination of formalized processes and full adaptation of appropriate tooling allows the team to automate most, if not all, of the actions.
Finally, at the fourth level of maturity (integrated), it is possible to build on top of the foundations of formal processes, expertise on tooling and automation to achieve automated interconnection between the three domains. For example, insights from Monitoring and Alerting on low model performance trigger new experiments on model training. The results of the new model are monitored and tracked to validate them against known performance metrics. Once sufficiently good, the new model can be automatically promoted to production, utilizing the automations of model Maintenance and Deployment to replace the underperforming model.
Read Further: Does your AI strategy match your company’s data maturity level?
Read Further: Why do we even need MLOps? Hidden Technical Debt in Machine Learning Systems
Feature and Experiment Tracking Domain in MLOps
Managing features and experiments is an integral part of MLOps that ensures optimal time-to-market for models. On the one hand, the main benefit of tracking features is reproducibility of data processing and feature extraction logic, referring to both calculation logic and business interpretation. On the other hand, the benefit of tracking experiments is that it allows for a systematic approach to model evaluation. All in all, standardization of methodology and, where applicable, cross-team collaboration are achieved via Feature and Experiment Tracking.

Stages:
- Proving business value (Manual stage): During the ideation and exploration phase, no tracking of features takes place and no experiments are formally carried out. Features might not even be stored in a database, but rather calculated on the fly, based on offline extracts. If any experiments are carried out, they aim at a functional PoC that can prove the idea’s business value, rather than at tracking results and parameters in a structured way.
- Introducing structure to the experiment process (Basic stage): A process starts to emerge as a response to the need for structure in the way experiments are carried out. New potential use cases need to be explored and improvement scenarios for existing ones need to be tested in a reproducible manner. At this stage, the logic of feature calculation should be tracked. The features themselves should be calculated and stored for future reference and reproduction of experiments, following a structured data architecture (i.e. medallion). Tracking experiments should also start at this stage, with or without the use of dedicated tools, for example tracking parameters, range of data used and results in an Excel file. It is important to note, that although such approaches can be good short-term solutions and can serve as an exploration opportunity, it is not advised that it becomes the norm. Adoption of experiment tracking tools and feature tracking could also be introduced at this stage as a starting point to formalize the iterative process of a use case and, more generally, the way of work of the team. Nevertheless, even simple tracking in Excel files might suffice when starting out, just make sure it does not become the norm.
- Annotating features, introducing lineage and automating experiments (Automated stage): As the team, and the company alongside it, mature and more use cases are implemented, the number of features grows. The sophistication of the calculated features increases as well. At this stage, annotating features and keeping track of feature lineage and usage should be formally introduced. This will allow for a holistic overview over the features, which can be crucial in the future as it can facilitate feature calculation improvements, use case maintenance and new ideas’ exploration, all the while minimizing unplanned disruptions. In addition, feature storage evolves towards a common resource for both production and development. In simple words, the same features should be accessible to both environments, thus avoiding duplication of work and discrepancies in the features between environments. On the experiment side, experiment tracking tools should be the way of work for the team. The capabilities, structure and overview provided by such tools make experiments easily reproducible and their insights actionable. Any important metadata generated by experiment runs should be tracked and made available for inspection and investigation. In total, at this stage, the tracking of features and experiments should be mostly automated and deliver insights that support the still-mostly-manual decision making process of use case development and maintenance.
- Automating and integrating into production process (Integrated stage): Available features should be fully annotated and their lineage clear to follow, based on a formalized process. This provides the team and any other interested party with a comprehensive reference guide on the available features, for the development of new use cases or dashboards. Approaches like feature catalogs or feature stores should be explored and potentially adopted, based on the needs of the team and the overall strategy of the company. Such a structured approach allows for a comprehensive overview of all features, leading to minimal duplication of effort for feature calculation. An added benefit is the ease of adjusting feature calculations while avoiding unintended implications in the use cases that utilize them. Experimentation is now aimed to be integrated into the use cases’ pipelines. This means that experiments can be automatically triggered and any decision making and actions regarding its results are automated, relying on an agreed upon and tested processes. For example, comparison of model performance should no longer be a manual process but an automated one, comparing against known thresholds and making decisions automatically to release new model versions. In reality, production-level updates usually follow a human-in-the-loop process, just to ensure smooth operation of all the automated processes while transitioning to new model or code base versions.
Monitoring and Alerting in MLOps
Monitoring model performance in production and alerting on irregularities ensures reliability and accuracy of models in production. The benefits practically include less downtime and shorter response times to errors. Eventually, tackling errors and problems in production can even become preventive, with sufficient monitoring, leading to higher user satisfaction, trust and significantly lower maintenance costs. Overall, Monitoring and Alerting facilitates feedback loops to improve model performance and tackle problems in production in a timely and cost-efficient manner.

Stages:
1) Monitoring is manual (Manual stage): When a team develops its first use cases, monitoring is restricted to checks on a process’ success or failure. Usually, dedicated team members, for example members of the development team, may be communicating issues with the rest of the team and manual actions are taken for debugging or further exploration and development. Therefore, any and all monitoring and alerting efforts are manual.
2) Introduce monitoring overviews (Basic stage): After the business value of some use cases is proven, they move towards a more complete product and users start to rely on them. At the same time, new use cases might be developed. At this stage, a concise overview of all use cases is needed in order to be able to respond quickly to possible issues and thus gain the trust of the users. To achieve this overview, dashboards can be introduced to keep track of main aspects of the use cases. Such dashboards can be populated by simple, manually executed and usually ad-hoc queries, and serve as a periodic checkpoint. Suggested monitoring actions aim mainly at the models’ statistical performance:
- Data sources: up-to-date/outdated, expected/unexpected format
- Execution state: success/failure
- Output: expected/unexpected results, accuracy metrics, error metrics, distribution of output
3) Standardize monitoring and automate alerting (Automated stage): As the use cases continue to grow in number and complexity, monitoring needs become more elaborate. Building on the foundation and insights of the manual queries of the previous stage, the team should now be able to identify the most crucial measurements to monitor for each of their use cases. Monitoring should also include technical performance of models, not only statistical performance. Depending on the team’s use cases, real-time tracking of model performance can also be introduced at this stage to support time-critical applications.
At the same time, typical issues and problems should be identified. They can be used to start generating automated alerts for frequent and expected issues. This will increase team productivity by removing unnecessary manual checks and informing team members of issues in production in a timely manner. The extra benefit is increased reliability for the team, since potential issues are dealt with before users experience unexpected disruptions.
Suggested Monitoring and Alerting steps are:
- Monitoring:
- Issues: types of issues/errors encountered
- Data sources: data drift, distribution changes
- Execution state: number of calls to the model, latency, resources tracking, runtimes
- Output: (live) update of output distribution, live class-, group-, cluster-wise distribution of predictions, accuracy and error
- Alerting:
- Mails for failures sent to developer team
- Scheduled notifications in daily used, message applications to provide updates on use case health
4) Fully integrate monitoring and automate alerting actions (Integrated stage): With automated dashboards and initial alerts being sent, the groundwork for fully automated Monitoring and Alerting has been set. The dashboards should by now be reliable and consistent, and common or frequent issues and errors should have been identified to an extent. The team has been taking manual or semi-automated actions based on the generated insights. Consequently, automating actions based on monitoring insights and issues or errors comes naturally as the next stage. This translates also to integration with other MLOps domains, like Experiment Tracking, since either information or action is required from those domains to achieve automation. Suggested Monitoring and Alerting steps:
- Alerting:
- Compile stakeholder lists for each use case, internal (devs) and external (users), to support later policy for direct notifications
- Utilize stakeholder list to apply a direct notification policy
- Actioning:
- Automate communication or incident submission to other teams that need to take action for an issue impacting the team’s use cases
- Automate model retraining based on performance drops, data drifts or distribution changes in the data
- Automate rollbacks in case of new models breaking your pipelines
Maintenance and Deployment in MLOps
Model deployment handles a trained machine learning model integration into a production environment to make predictions and interact with business systems. Model maintenance involves updating and refining models to maintain accuracy and effectiveness amidst changing data patterns and operational environments.
The timely adaptation of production models is achieved through deployment automations and utilization of the two other principles. It can be seen as the accumulation of MLOps efforts as all insights are translated into actionable points with the aim of maintaining model relevance and performance in highly volatile environments.
Stages:
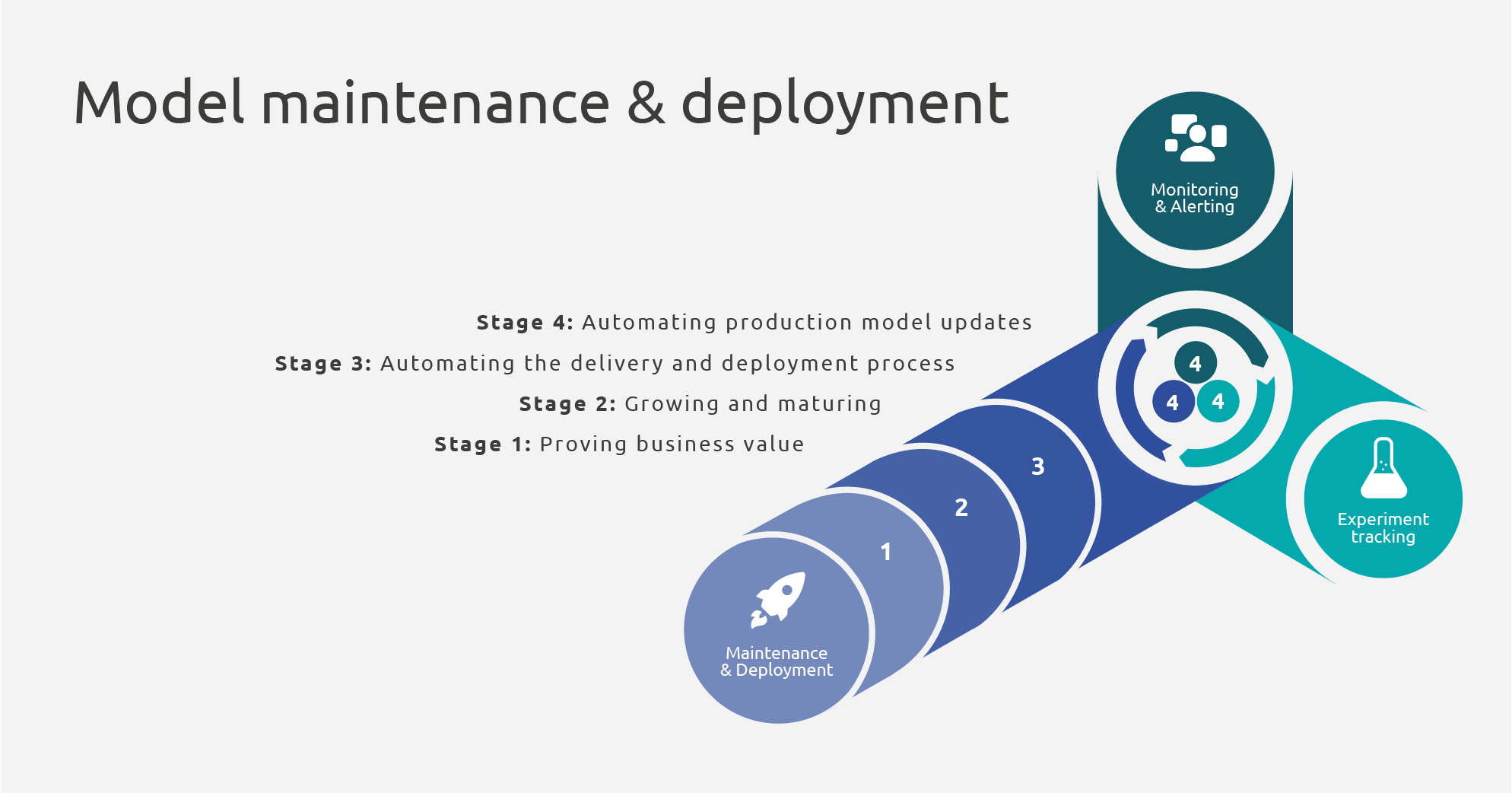
- Proving business value (Manual stage): Initially, the goal is to make the current, still PoC or MVP-level use case available and thus start proving its business value. At this stage, code versioning tools should be used for code development. It is usually the case that the model of the use case does not need to be updated often, and any maintenance or fixes are performed only when needed and not as a priority. The needs of the model are thus minimal and all deployment-related processes are manual.
- Growing and maturing (Basic stage): The use case grows and matures as its value is proven and its contribution is recognized. To achieve this sustainably, the team requires support in handling the complexities of the machine learning process. Model versioning tools should be introduced to support the team, with a focus on tracking and organizing models and on formulating a simple, although possibly still manual, model development and deployment process. Thus, reacting to model fixes, improvements and change requests will be handled in a structured way. As the needs of the team and the users grow, these first steps will serve as the foundation towards models that can be increasingly robust, transparent, production-ready and reliably delivered to production.
- Automating the delivery and deployment process (Automated stage): At this stage, robustness and readiness of use cases’ models take higher priority for the team and the users. The use of supporting tools should be formally integrated in the way of work of the team. Automation is also introduced to the process to support the team and remove repetitive, error-prone, manual actions. Good practices such as CI/CD should also be introduced, to ensure that faulty or underperforming models do not reach production. The previously manual deployment process should now be automated. At this stage, Monitoring and Alerting and Feature and Experiment Tracking are key factors in manually triggering the automated process of model development and deployment, as they provide the tools and insights to evaluate model performance.
- Automating production model updates (Integrated stage): At the final level of maturity, both decision making and model development and deployment are connected and automated. This is the natural next step after automating the development and deployment process and testing its reliability by manually triggering new model development and, potentially, deployment. This stage requires a high level of maturity of both Monitoring and Alerting and Feature and Experiment Tracking, as it essentially automates their actions. For example, significant model performance deterioration is automatically detected via Monitoring and informs automated model retraining via Alerting. The resulting model is evaluated via Experiment Tracking and its potential promotion to production is either automated or requires only human approval - thanks to automated model deployment.
Conclusion
MLOps is often seen as an intricate, interconnected pipeline with a variety of tools attached to its different components that need to be simultaneously developed. This presentation, however, rarely matches the needs and reality of data teams.
Feel free to approach MLOps as it fits your team, applying best practices to the maturity level that suits your team’s needs (and not just for the sake of implementing them). Each of the MLOps domains discussed above can reach a different level of maturity at a different pace. MLOps best practices can just as easily be adopted individually, although the final goal is to ultimately achieve a level of connection between them. For example, Monitoring and Alerting can support a team on its own but its outputs can also automatically inform deployment decisions, when connected with Model Maintenance and Deployment.
In the end, by definition, MLOps is a paradigm that aims to deploy and maintain machine learning models in production reliably and efficiently. If it does not meet your needs, it will be neither reliable nor efficient.