
Artificial Intelligence has greatly accelerated the development of autonomous systems over the past few years. A few years ago Xomnia sought to push the boundaries of modern-day artificial intelligence by developing an autonomous boat run end-to-end by Artificial Intelligence. Meaning that one A.I. does it all: with only camera images as input, the boat can safely navigate to the canals of Amsterdam. To train this A.I. you only need example images (gathered data from a human test driver) with the corresponding steering commands. Called supervised learning, this A.I. learns by human example.
During this time, there were other interested parties in this technology. One of these helped us to start our new venture Shipping Technology, focused on bringing cutting-edge artificial intelligence to inland shipping. The focus of this article, however, is how we managed to improve the A.I. in different ways and apply it to a different vehicle. Not only does it teach itself how to drive a train, but it also manages to optimize further parameters, like power usage, way beyond human capabilities.
What is Artificial Intelligence/Deep Learning?
Let’s talk a bit about what the term artificial intelligence means in current time. As in earlier days, we applied data in a useful way in many different fields: predicting stock and housing prices, forecasting and search analytics. Every field had its own set of tools that worked really well, and these tools were generally well understood in how they learn, and more specifically, what exactly these models learn to come to a specific conclusion. These “classical” methods are often referred to as data science or machine learning and required domain knowledge on what parameters (often called features) contributed to accurately solve the problem. For instance, we specifically had to designate that the number of bedrooms in a house was information needed to be able to predict housing prices on new houses and had to prune these from an often varied dataset.
Because of advancements in computer processing power and better availability of data, most of these methods have been replaced by a field called Deep Learning, which is taking the world by storm and is powering the AI revolution.
In the simplest form, convolutional neural networks are the working horse of the deep learning field. These are very deep neural networks with image filters that perform feature extraction by themselves. In short: instead of having to specifically designate what’s important to solve the problem, these neural networks pick the important parts from the data by themselves. And we’ve found that these self-learned features are often more effective at solving problems than human engineered ones.
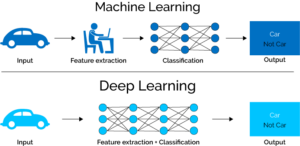
Supervised and Unsupervised
In the field of deep learning, we differentiate between two different branches of artificial intelligence. Supervised AI is AI that learns by example, here the correct answer is something we know during training. If we want an AI to learn the difference between cats and dogs, we feed it many images of cats and dogs until it has understood the concept. The same is true for Xomnia’s self-driving boat: we feed a convolutional neural network a lot of video material from a human test driver where the correct answer is the human steering angle.
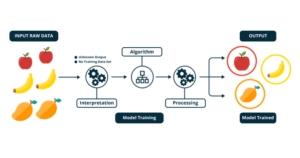
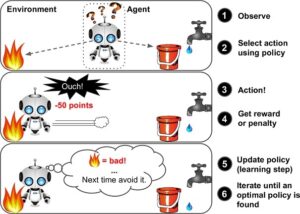
Unsupervised AI is the polar opposite: there is no correct answer. Instead, the AI is dropped in an environment where it can play around and get feedback on its actions. This is done with a reward function. A mathematical function that returns a “score” on how well its actions are. And during training, it wants to maximize the score in a session. You often see these kinds of AI in game-like scenarios because the reward is a very tangible thing: I eliminated an enemy so I get +1 reward. This is a lot harder to shape in real-life and this is applied less in any practical scenario. Which is a shame, because we often see super-human performance when such an AI has been trained.
Pushing boundaries
Here at Xomnia, we strive above the mean when we were asked if we could apply our AI on trains by one of our interested parties. We didn’t want the AI to just drive it, we wanted it to drive it as good as such a vehicle can be driven. We knew the true value of an autonomous system was how it could be pushed to drive more efficiently and so our eyes turned to reinforcement learning. We only had to shape our “reward” in the correct way. This was done by providing a reward for the amount of distance traveled combined with a penalty for power usage. The AI got rewarded for every meter it successfully traveled but punished for using power. The more power the AI would use, the less reward it would receive from correctly traveling along the tracks. This is a punishment that is called “reward discounting”. If the AI would use a lot of power at the start of the session, the penalty is minor, but it builds up the longer the session goes on, so near the end, an inefficient policy would end up not netting the AI any reward.
There was one downside to reinforcement learning, and that is the time required. One big success story of reinforcement learning was Alpha Go. The AI made by Google Deepmind to play the game of Go at a superhuman level. This agent was able to beat the world champion at Go, but it took an extraordinary amount of time for the agent to reach that level of play: over a month of continuous training.
Realistically, we couldn’t afford spending months (or years in the worst case scenario) trying different reward functions to see what would work. So we worked on the problem on why these agents need to much time to train. The reason is that these networks do two things during training: they try to predict the score a current action would net them and they try to predict how good their next state would be after they made their move. Because it’s all packed into one neural network, it would mean that adjustments made to the network to get closer to one of these things, would mean drifting away from the other.
You can compare this to a cowboy trying to catch a cow. As soon as we put a step closer to the cow, he also runs off.
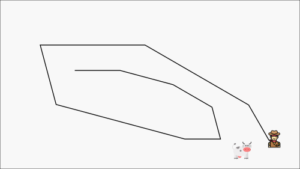
If we would plot our training progress we would see an oscillating path like this. We get closer to the target over time, but because this target is constantly moving (we drift away from one parameter by getting closer to another) it takes us a long time to actually get there.
For optimizing two parameters, we just needed an elegant solution: we implemented a network that splits off into two at the final layers, where each split optimizes one parameter.
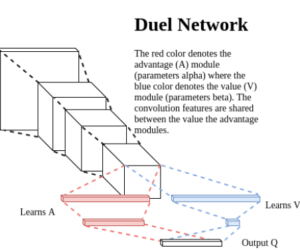
Here one network (A) learns the short term parameter (how good is my current action going to be), and the other network (V) learns the long-term parameter (how good is my next state going to be).
Results
The double network architecture resulted in a drastically shorter training time. Our new reinforcement learning AI learned to drive a train by itself (and from scratch) in 12 hours. Opposed to other methods which require months to produce a stabilizing agent. Furthermore, wrapping power usage in the internal reward function reduced power consumption by 18% over a human test driver.
Over the next months, we will train the AI in more difficult driving scenarios and see if we can reduce power consumption even more by tweaking the reward function and the internal network architecture.